基于telethon的Telegram爬虫

为了阻止人工智能接管世界 我不得不去 Telegram 爬取大量 Dog 图片来优化我的神经网络
*此脚本主要用到 Telegram的python开源工具包telethon,以及asyncio等实现异步并发下载电报消息。
测试环境 debian 10 & Python 3.8.3*
导包
- 主要用到 Telegram的python开源工具包
telethon,以及异步IO工具包asyncio等,缺啥补啥。
import difflib
import os
import re
import time
import asyncio
import asyncio.subprocess
from telethon import TelegramClient, events, errors
from telethon.tl.types import MessageMediaWebPage
授权
api_id = 1234567 # your telegram api id
api_hash = '123456789asdfg' # your telegram api hash
bot_token = '13454236:ADFAGADAF' # your bot_token
admin_id = 12314567 # your chat id
自定义配置
- 根据需要修改
save_path = '/var/downloads' # 文件下载路径
max_num = 10 # 同时下载数量
filter_file_name = ['png',] # 过滤特定格式的文件
filter_list = ['猫猫', '\n'] # 文件名过滤
定义函数
- 文件名处理函数等
# 文件夹/文件名称处理
def validateTitle(title):
r_str = r"[\/\\\:\*\?\"\<\>\|\n]" # '/ \ : * ? " < > |'
new_title = re.sub(r_str, "_", title) # 替换为下划线
return new_title
# 获取相册标题
async def get_group_caption(message):
group_caption = ""
entity = await client.get_entity(message.to_id)
async for msg in client.iter_messages(entity=entity, reverse=True, offset_id=message.id - 9, limit=10):
if msg.grouped_id == message.grouped_id:
if msg.text != "":
group_caption = msg.text
return group_caption
return group_caption
# 获取本地时间
def get_local_time():
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 判断相似率 ,用于过滤标题
def get_equal_rate(str1, str2):
return difflib.SequenceMatcher(None, str1, str2).quick_ratio()
# 用于跳过特定格式文件
def skip(file_name):
for filter_file in filter_file_name:
if file_name.endswith(filter_file):
print('skip .'+filter_file + ' file')
return True
待下载队列
- 队列里的数据结构 [message, chat_title, entity, file_name]
queue = asyncio.Queue() # 待下载队列
handler
handler相当于一个传话员,将你的命令处理过后,生成一个 ⬆queue待下载队列,供⬇worker使用-
通过与 Telegram 客户端的 bot 交互,告诉脚本要爬哪些内容,并依次放入queue队列
- 消息格式
/start <群组链接> <从第N条消息开始下载>,如图: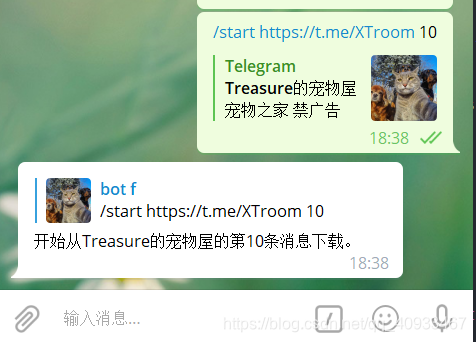
@events.register(events.NewMessage(pattern='/start', from_users=admin_id))
async def handler(update):
#*********************处理bot消息****************************#
text = update.message.text.split(' ')
if len(text) == 1:
await bot.send_message(admin_id, '参数错误,请按照参考格式输入:\n\n '
'<i>/start https://t.me/fkdhlg 0 </i>\n\n'
'Tips:如果不输入offset_id,默认从第一条开始下载。', parse_mode='HTML')
return
elif len(text) == 2:
chat_id = text[1]
try:
entity = await client.get_entity(chat_id)
chat_title = entity.title
offset_id = 0
await update.reply(f'开始从{chat_title}的第一条消息下载。')
except:
await update.reply('chat输入错误,请输入频道或群组的链接')
return
elif len(text) == 3:
chat_id = text[1]
offset_id = int(text[2])
try:
entity = await client.get_entity(chat_id)
chat_title = entity.title
await update.reply(f'开始从{chat_title}的第{offset_id}条消息下载。')
except:
await update.reply('chat输入错误,请输入频道或群组的链接')
return
else:
await bot.send_message(admin_id, '参数错误,请按照参考格式输入:\n\n '
'<i>/start https://t.me/fkdhlg 0 </i>\n\n'
'Tips:如果不输入offset_id,默认从第一条开始下载。', parse_mode='HTML')
return
#*********************处理bot消息****************************#
if chat_title:
print(f'{get_local_time()} - 开始下载:{chat_title}({entity.id}) - {offset_id}')
last_msg_id = 0
async for message in client.iter_messages(entity, offset_id=offset_id, reverse=True, limit=None):
if message.media:
# 如果是一组媒体
caption = await get_group_caption(message) if (
message.grouped_id and message.text == "") else message.text
# 过滤文件名称中的广告等词语
if len(filter_list) and caption != "":
for filter_keyword in filter_list:
caption = caption.replace(filter_keyword, "")
# 如果文件文件名不是空字符串,则进行过滤和截取,避免文件名过长导致的错误
caption = "" if caption == "" else f'{validateTitle(caption)} - '[
:50]
file_name = ''
# 如果是文件
if message.document:
if type(message.media) == MessageMediaWebPage:
continue
if message.media.document.mime_type == "image/webp":
continue
if message.media.document.mime_type == "application/x-tgsticker":
continue
for i in message.document.attributes:
try:
file_name = i.file_name
except:
continue
if file_name == '':
file_name = f'{message.id} - {caption}.{message.document.mime_type.split("/")[-1]}'
else:
# 如果文件名中已经包含了标题,则过滤标题
if get_equal_rate(caption, file_name) > 0.6:
caption = ""
file_name = f'{message.id} - {caption}{file_name}'
elif message.photo:
file_name = f'{message.id} - {caption}{message.photo.id}.jpg'
else:
continue
#****************核心部分******************#
await queue.put((message, chat_title, entity, file_name))
last_msg_id = message.id
await bot.send_message(admin_id, f'{chat_title} all message added to task queue, last message is:{last_msg_id}')
worker
- 经过handler的处理后的queue,
client.download_media - 这里改进了原作者代码中的文件格式过滤部分,(见注释)
async def worker(name):
while True:
# 将queue队列中的信息分别提取
queue_item = await queue.get()
message = queue_item[0]
chat_title = queue_item[1]
entity = queue_item[2]
file_name = queue_item[3]
#此处对原代码(以下注释)进行优化,使其不会因过滤文件太多而停止运行
if skip(file_name):
continue
# for filter_file in filter_file_name:
# if file_name.endswith(filter_file):
# print('find')
# return
dirname = validateTitle(f'{chat_title}({entity.id})')
datetime_dir_name = message.date.strftime("%Y年%m月")
file_save_path = os.path.join(save_path, dirname, datetime_dir_name)
if not os.path.exists(file_save_path):
os.makedirs(file_save_path)
# 判断文件是否在本地存在,如果存在,则移除重新下载
if file_name in os.listdir(file_save_path):
os.remove(os.path.join(file_save_path, file_name))
print(f"{get_local_time()} 开始下载: {chat_title} - {file_name}")
# 核心部分
try:
loop = asyncio.get_event_loop()
task = loop.create_task(client.download_media(
message, os.path.join(file_save_path, file_name)))
await asyncio.wait_for(task, timeout=3600)
# 核心部分
except (errors.FileReferenceExpiredError, asyncio.TimeoutError):
print(f'{get_local_time()} - {file_name} 出现异常,重新尝试下载!')
async for new_message in client.iter_messages(entity=entity, offset_id=message.id - 1, reverse=True,
limit=1):
await queue.put((new_message, chat_title, entity, file_name))
except Exception as e:
print(f"{get_local_time()} - {file_name} {e}")
await bot.send_message(admin_id, f'Error!\n\n{e}\n\n{file_name}')
finally:
#确保任务正常结束
queue.task_done()
main
- 主调函数,通过 id 和 token 等启动 telethon 的 bot。
if __name__ == '__main__':
# 通过 id 和 token 等启动 bot 机器人
bot = TelegramClient('telegram_channel_downloader_bot',
api_id, api_hash).start(bot_token=str(bot_token))
client = TelegramClient(
'telegram_channel_downloader', api_id, api_hash).start()
bot.add_event_handler(handler)
# 任务列表
tasks = []
try:
# 启动 max_num 个 task
for i in range(max_num):
loop = asyncio.get_event_loop()
task = loop.create_task(worker(f'worker-{i}'))
tasks.append(task)
print('Successfully started (Press Ctrl+C to stop)')
client.run_until_disconnected()
# 确保程序正确终止
finally:
for task in tasks:
task.cancel()
client.disconnect()
print('Stopped!')
本文代码来源Github